相关知识
工具
- Python3
- TensorFlow 1.5(GPU版本需安装 cuda 和 cudnn ,请注意 cuda 和 cudnn 版本之间的兼容性)
神经网络
主要参考
验证码类型
数字四则运算,有噪点干扰,输出计算结果。

输出:2+5-8=-1 英文字母 + 数字验证码,包含 5 个字符,有噪点干扰,文字无旋转形变,验证方法为要求用户输出验证码中的字符,大小写不限(为验证方便可统一转为大写)。

输出:YFQKX 英文字母 + 数字验证码,包含 4 个字符,有噪点干扰,文字有旋转形变,验证方法为要求用户输出验证码中的字符。

输出:JN2M 中文验证码,包含 4 个中文汉字,有噪点干扰,验证方法为要求用户选出4个汉字中被旋转90度的那一个(四个汉字从左到右序号为 0,1,2,3,输出被旋转的汉字序号即可)。

输出:2 中文验证码,包含 4 个中文汉字和 9 个中文单字,有噪点干扰,文字有旋转形变,验证方法为要求用户从 9 个单字中从左到右按顺序选出验证码中的汉字,输出相应的单字序号。

第 1 张大图是验证码图片,后面 9 张是单字图片,按顺序各自拥有序号 0-8 输出:0138
解题思路
第 1 题题干只给出了“验证码包含一个四则运算,包含三个数字和两个运算符,运算符不包括除号,运算本身不包含括号”这样的信息,所以 无从得知验证码算式字符串的固定长度 。因此自然地想到可以将图片进行分割再逐一识别,鉴于第一类图片噪点较少,经过简单的灰度化->二值化->去噪之后就可以对图片进行分割。将分割之后的图片作为样本数据进行深度学习,可以得到一个能够识别10个数字和3个符号的模型。在对一个验证码进行预测的时候,首先先经由前面相同的图片预处理步骤,产生分割后的图片;然后用学习到的模型逐一预测,再将预测后的结果组合起来,就能得到验证码图片中的算式字符串了;最后计算算式的值即可。
第 2、3 题都是给定了验证码中字符的固定长度,且识别的内容是26个英文字母,因此是典型的分类问题。所以可以直接通过end2end(端到端)的方法,不对原始图像进行去噪等处理,在将图片灰度化后就喂给神经网络进行学习,如此便可以学习出一个良好的识别模型。
第 4 题要求识别出旋转过后的汉字的位置,因为汉字的个数是固定的,这表明识别的结果也被限定在了一定范围内,即 0,1,2,3。从这个角度来看,这题也是一个分类问题,因此这题也可以通过端到端的方法来实现。
第 5 题每一个验证码给出了十张图片,一张四个汉字九张单个汉字,要求从九个单字中按顺序选出验证码中的汉字。这题可以先将大图片(四个汉字)进行去噪并 分割 ,然后将单字图片和分割后的图片两两一组作为训练样本输入到神经网络中,让神经网络学习图片之间的 相似度 。然后用学习到的模型将分割后的汉字和其余九张汉字进行相似度对比,筛选出相似度最高的图片,记录下序号即可。
解题步骤
解题共同步骤
划分训练集和验证集:
从企业所给图片中抽取 75% 用于训练集,剩下 25% 作为验证集,为了反映出良好的分类效果,所有数据的选取随机进行,从而使实验数据更加可靠。
图片预处理(每题各不同)
训练模型:
训练图片的过程是系统构造模型的过程,是验证码识别系统的核心。系统重点实现 CNN 卷积神经网络。将预处理过的图片输入 CNN 网络中后,整个训练图片的过程就是构造识别模型的过程。
我们采用 TensorFlow 框架作为实现深度学习的工具。TensorFlow 表达了高层次的机器学习计算,具备更好的灵活性和可延展性。TensorFlow 一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型。
训练模型首先需要构造一个合适的模型,TensorFlow 框架中提供了许多现成的函数帮助开发者快速地构建一个网络结构,如用于CNN网络构建的 tf.nn.conv2d、tf.nn.max_pool、tf.nn.relu和tf.layers.dense 等。利用 TensorFlow 提供的便利函数,我们可以高度自定义网络结构,解决不同的题目会构造相应的网络结构。
在 TensorFlow 中,结点权重和偏差值以变量的形式存储,即 tf.Variable 对象。 在数据流图调用 run() 函数的时候,这些值将保持不变。以初始值运行神经网络之后,会得到一个实际输出值 y’,而我们的期望输出值是 y,这时我们需要做的就是计算两者之间的误差,并通过调整权重等参数使之最小化。一般计算误差的方法有很多,根据不同的学习问题将采用不同的计算误差方法。得到误差之后,接下去的任务就是如何最小化误差,我们采用了 Adam 优化法,即自适应矩估计的优化方法,具体在 TensorFlow 中的体现是 tf.train.AdamOptimizer(learning_rate).minimize(loss) 函数。这里我们需要传入 learning_rate 参数以决定计算梯度时的步进长度。非常方便的一点是, AdamOptimizer() 函数封装了两种功能:一是计算梯度,二是更新梯度。换句话说,调用该函数不但能计算梯度值,还能将计算结果更新到所有 tf.Variables 对象中,这一点大大降低了编程复杂度。
在进行实际的模型训练之前,还需要将数据分成 batch,即一次计算处理数据的量。这时就体现了之前定义 tf.placeholders 的好处,即可以通过 placeholders 定义中 的 “None” 参数指定一个维度可变的 batch。也就是说,batch 的具体大小可以等后面使用时再确定。这里我们在模型训练阶段传入的 batch 较小,而验证阶段的 batch 数量会大一点,因此需要使用可变 batch。随后在训练中,我们通过自定义函数来获取每次处理的真实图片数据。
第一题步骤
图片预处理:
图片灰度化:
由于验证码的颜色对于验证码识别没有太大帮助,反而会造成计算量的增加,因此第一步需要把带有 rgb 三通道的图片转换成单通道的灰度图。各大图片库都支持将图片灰度化,这里用到的是 python 中的 skimage 库中的 color.rgb2gray(img) 方法。
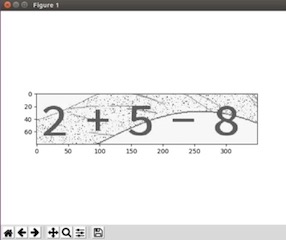
灰度化 otsu二值化:
这一步需要把验证码的前景和背景分开,研究第一题验证码图片的灰度图可以发现灰度图中有两个峰值,恰好 otsu 方法可以有效处理这种类型的图片。这里用到 skimage 中的 filters.threshold_otsu(img) 方法,它返回一个阈值,然后将大于这个阈值的像素置为白色 (255或1.0),小于阈值的像素置为黑色 (0.0)。经过这些操作就可以将图片二值化。
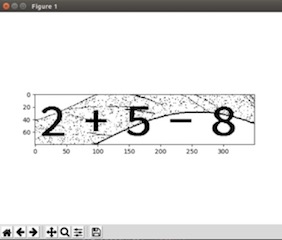
otsu二值化 八邻域去噪点:
在二值化之后的图片中仍然存在孤立噪点和干扰线,这一步要做的就是将图片中的孤立噪点去除。由于图片已经过二值化,因此利用八邻域可以轻松去除孤立噪点。

八邻域去噪 中值滤波:
去除完孤立噪点之后还有一些干扰线,由于图片已经去除了噪点且二值化,所以这个时候采用中值滤波可以有效地去除干扰线。

中值滤波 投影法分割:
由于第一题的字符不是定长的,所以需要对图片进行分割,在经过前面的处理之后,图片应该是只包含黑白的干净图片,其中字符均为黑色,背景为白色;这个时候采用投影分割就可以有效地分割出各个字符。

投影法分割
训练模型:
编写一个 python 脚本来随机选取预处理过后的数据,并将数据组合成合适大小的 batch。
模型结构如图
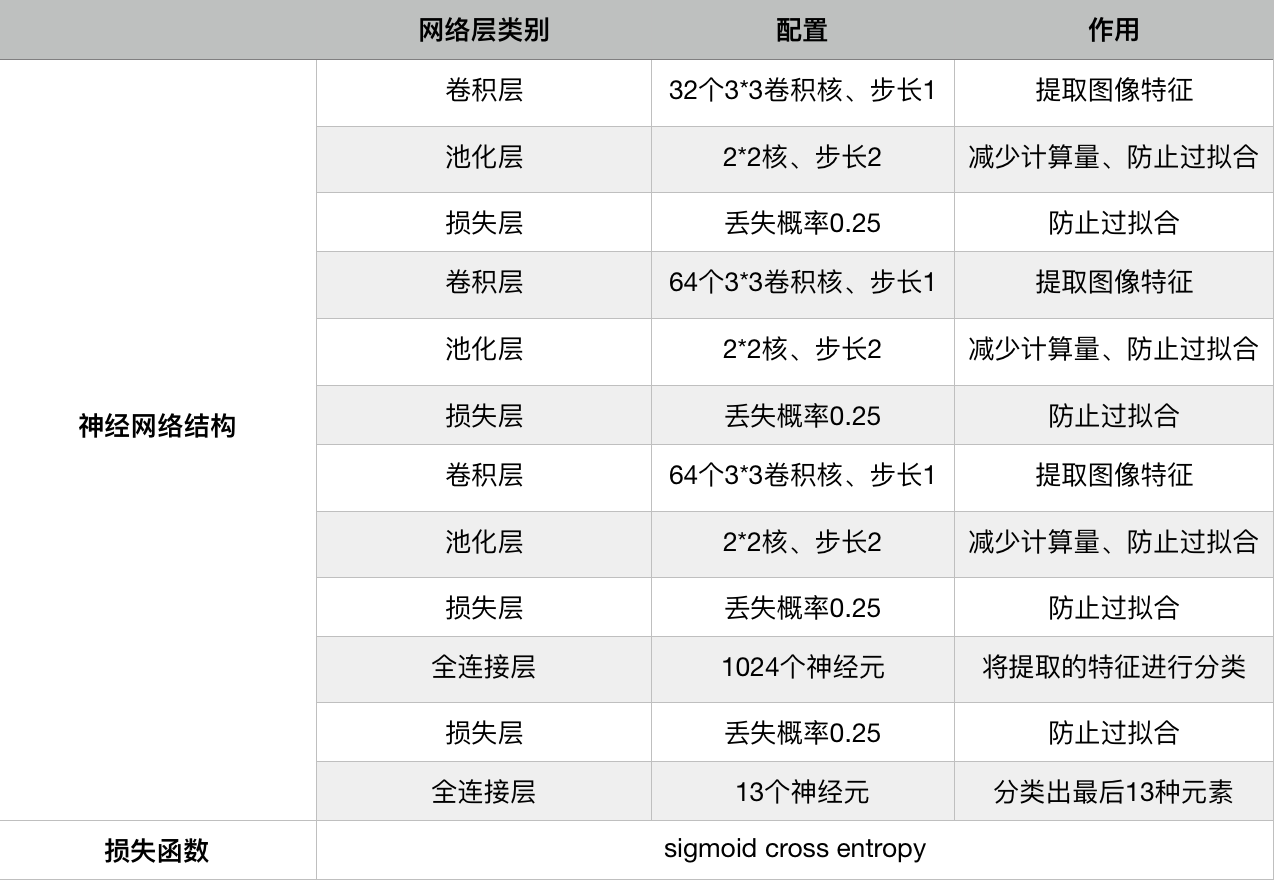
以 10 个数字(0~9)和 3 个运算符(+、-、*)作为分类的最后结果。
将数据喂入神经网络,用 sigmoid cross entropy 来计算误差,利用 Adam 优化器来降低误差,由此来训练一个模型。
训练出的模型是针对分割后的单个字符进行识别,因此最终的识别结果需要组合成一个式子,然后用 python 自带的 eval() 函数来计算出字符串式子的值,最后拼接成一个完整的预测字符串。
第二题步骤
训练模型:
编写一个 python 脚本来随机选取灰度化后的图像数据,并将数据组合成合适大小的 batch。
模型结构如图
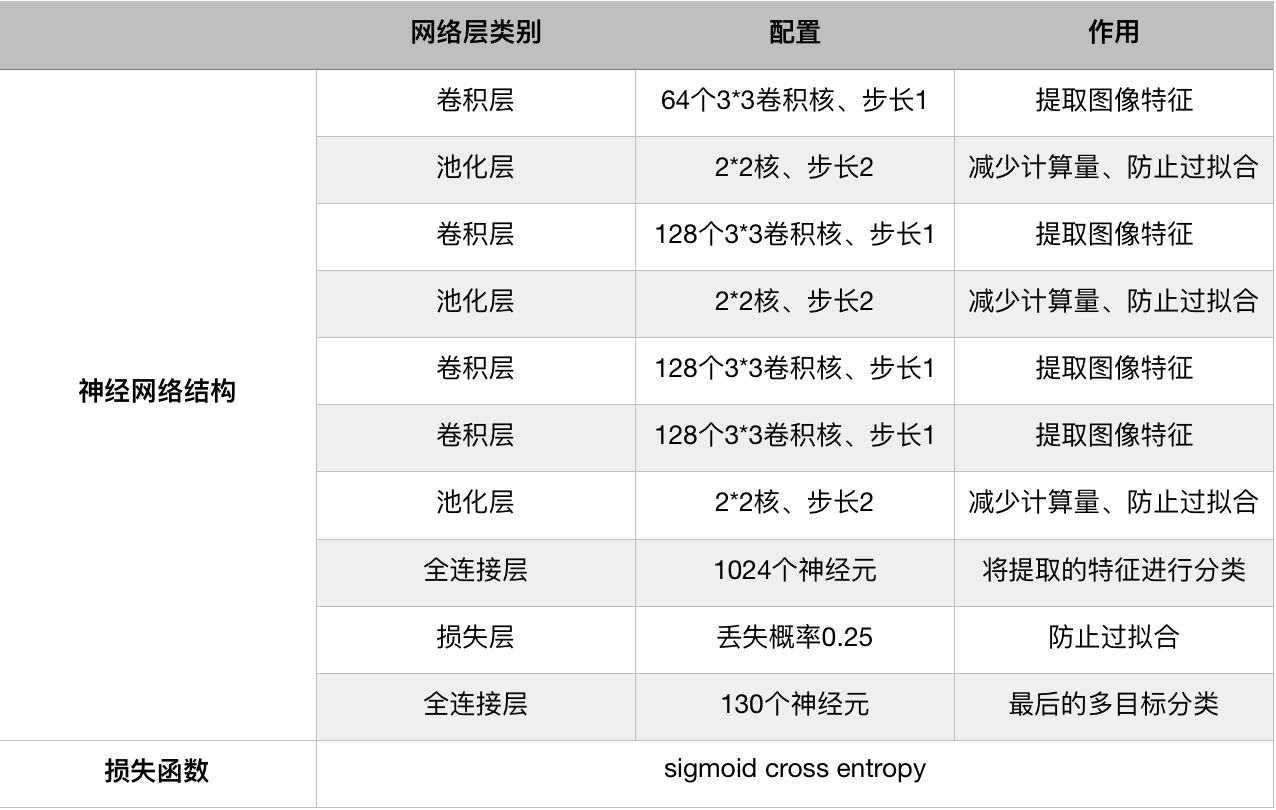
因为有5个字符,每个字符都是从 26 个英文字母中进行选择,所以最后的分类结果是一个 26*5 维的向量。
将数据喂入神经网络,用 sigmoid cross entropy 来计算误差,利用 Adam 优化器来降低误差,由此来训练一个模型。
训练出的模型可以端到端的预测本题的验证码图片。
第三、四题步骤
思路与第二题大同小异,故不再赘述。
第五题步骤
图片预处理:
图片灰度化:(详见第一题)
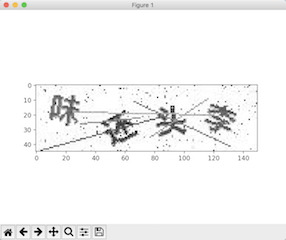
灰度化 图片膨胀:
膨胀操作会使得图像中的亮区开始扩展,由于本题的背景相对前景来说较亮,所以可以通过膨胀操作来增大前景和背景的区别。同时膨胀操作也有去除孤立噪点,使噪点背景化的效果。
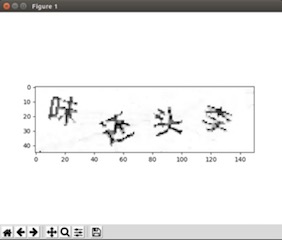
膨胀 八邻域去噪:(详见第一题)
在膨胀处理过后可以直观看出图片中还有一些脏噪声,可以使用八邻域的方法去除这些噪声。

八邻域去噪 图片腐蚀:
对大致去除孤立噪点后的图片采用腐蚀操作,可以使图片中的字更加清晰,突出前景。
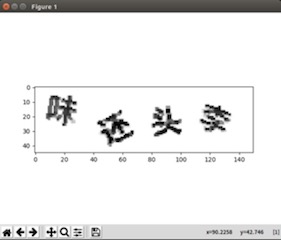
腐蚀 分割:
将图片 宽度四等分 ,按照等分的宽度来切割图片。
训练模型:
编写一个 python 脚本来随机选取预处理过后的数据。
模型结构如图
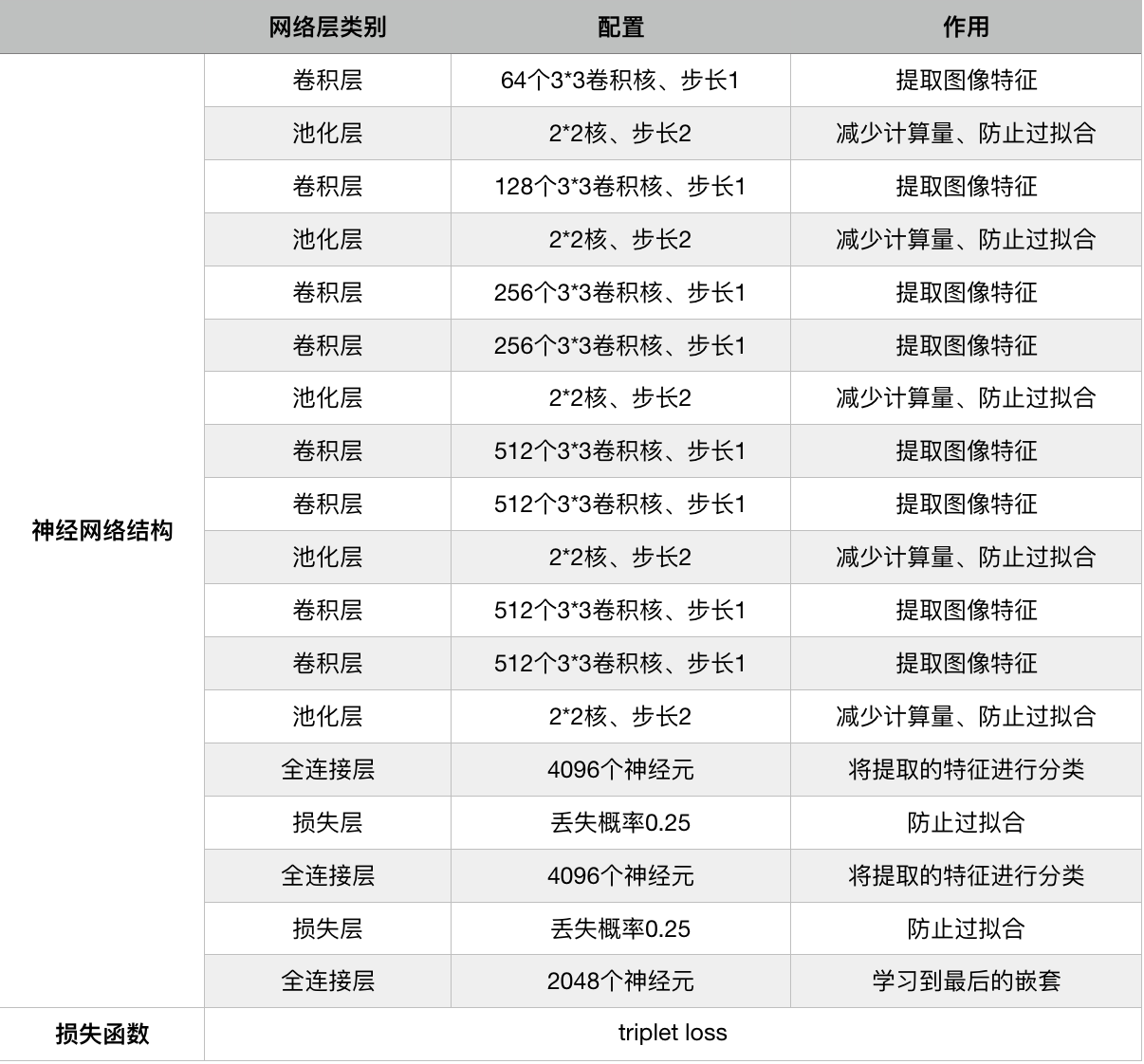
将数据喂入神经网络,损失函数采用 triplet loss,利用 Adam 优化器来降低损失,由此来训练模型中的参数。
输入一张图片到模型中将产生这张图片的嵌套(embedding),同时输入多张图片,然后根据图片的嵌套来计算图片之间的距离,由此可以判断图片的相似度,识别出验证码的序号。
结果分析
第一题
训练损失:
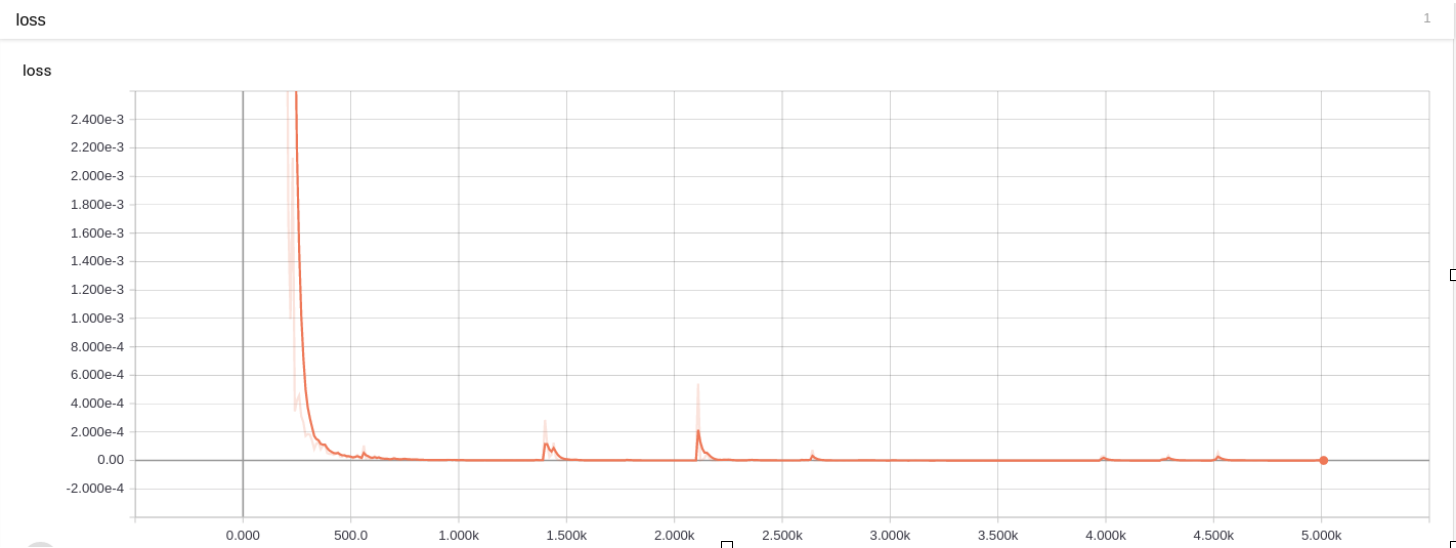
第 1 题损失图 训练准确率:
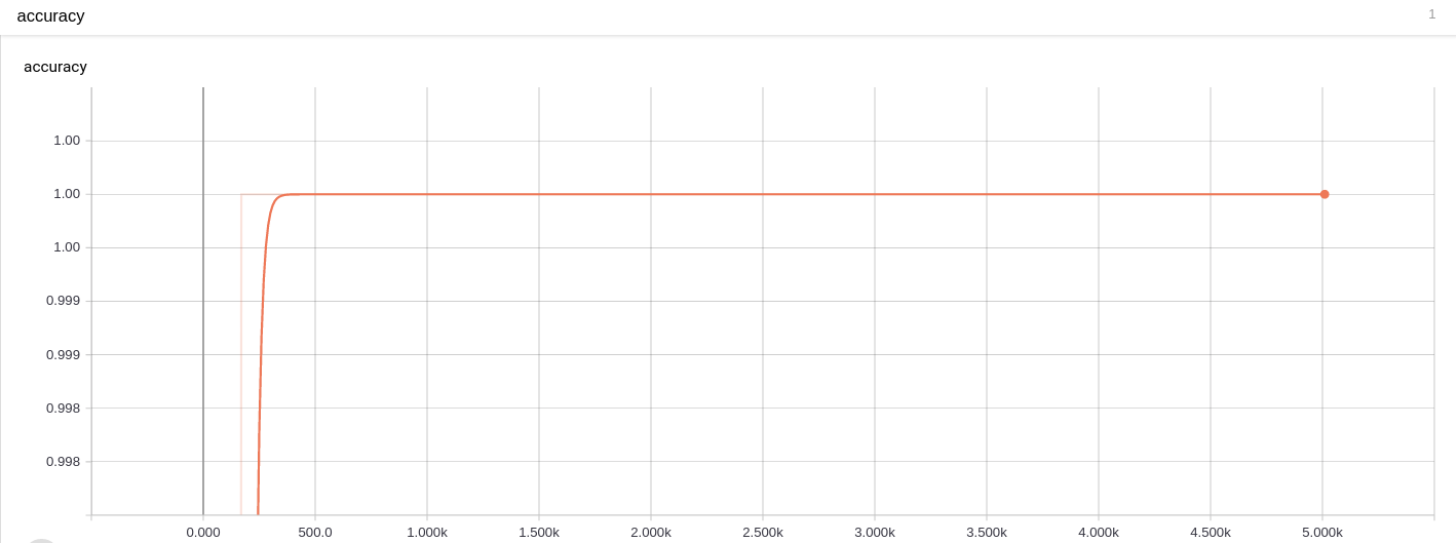
第 1 题准确率图
第二题
训练损失:
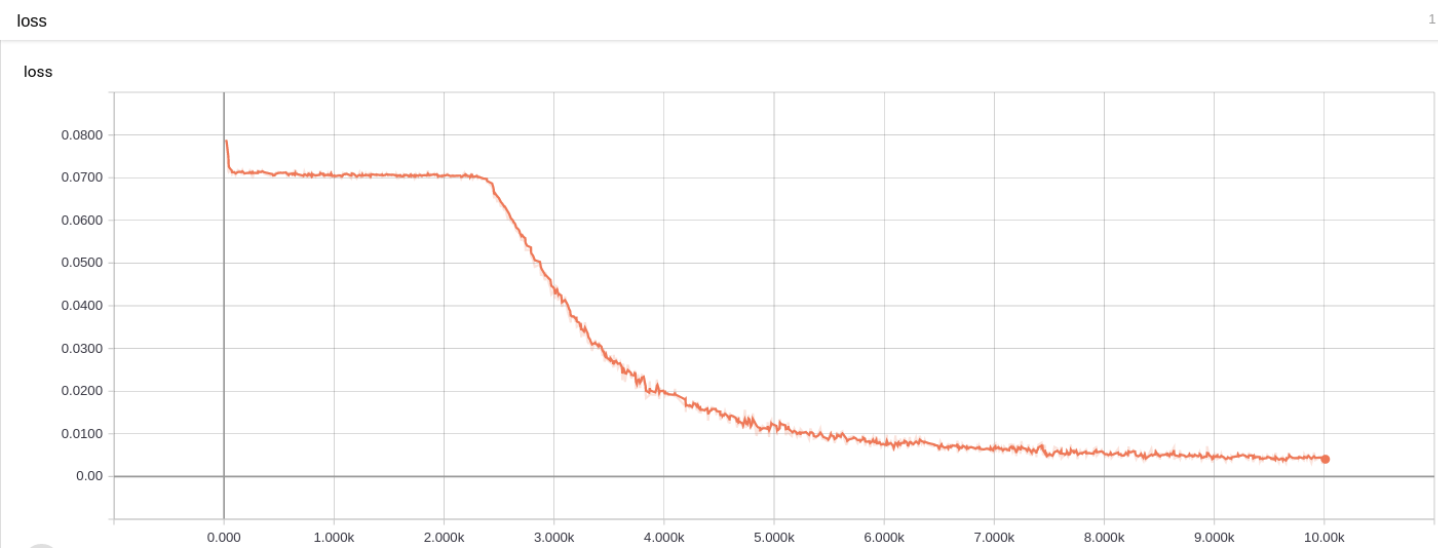
第 2 题损失图 训练准确率:
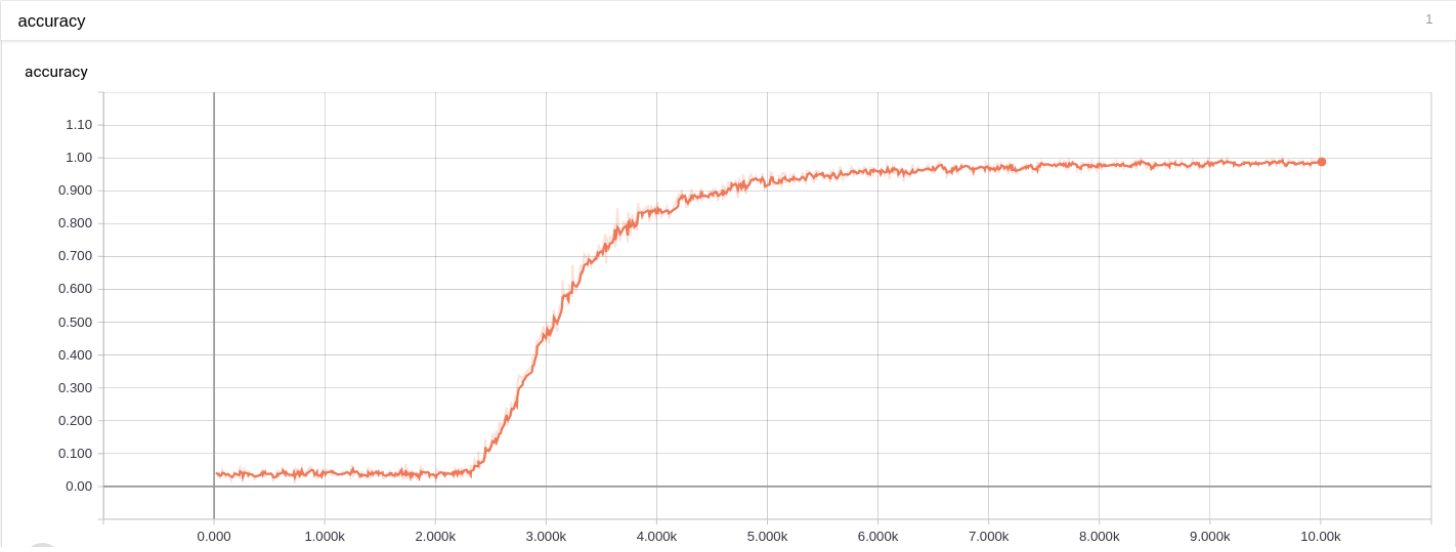
第 2 题准确率图
第三题
训练损失:
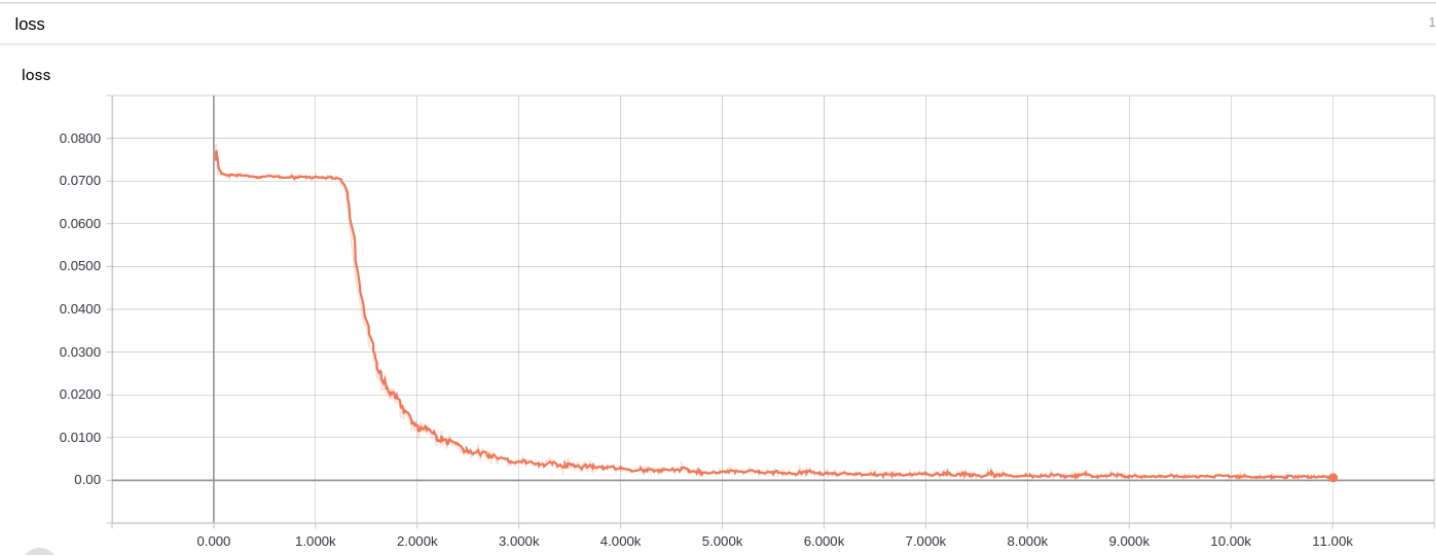
第 3 题损失图 训练准确率:
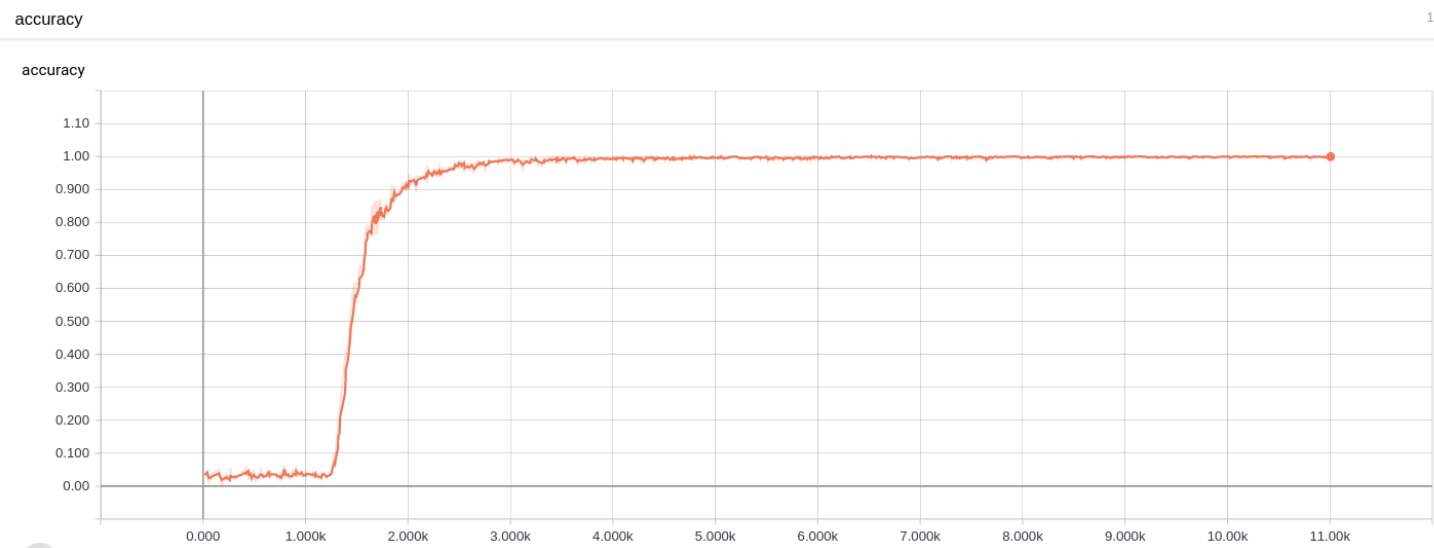
第 3 题准确率图
第四题
训练损失:
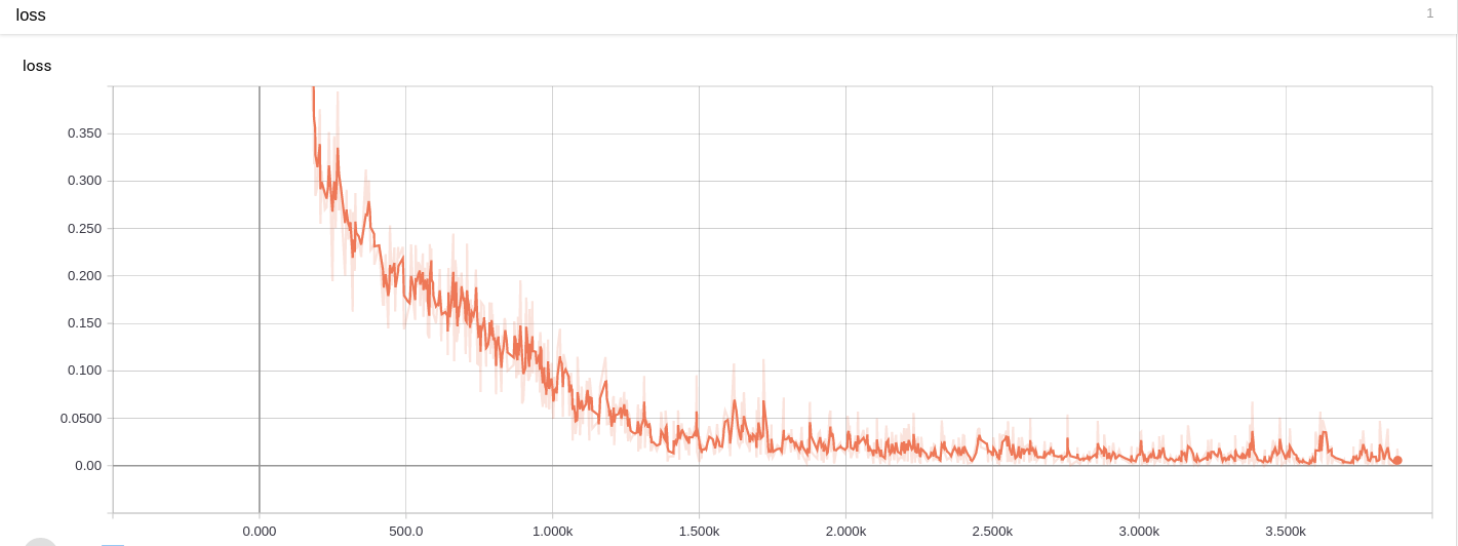
第 4 题损失图 训练准确率:
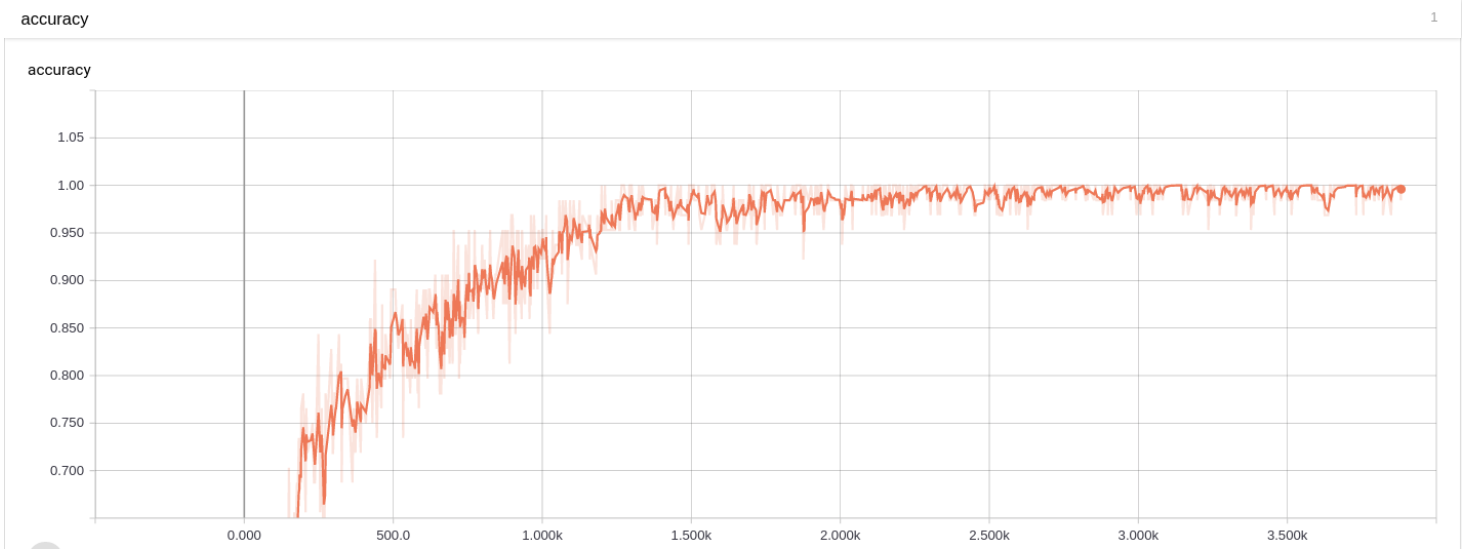
第 4 题准确率图
第五题
由于第五题训练的轮数太多,进行了多次的断点训练,没有完整记录下训练中的损失和准确率数据,因此并没有用 TensorBoard 生成曲线图。
第五题大概训练了 600k 轮次,最后在验证集上也只达到了 93% 的准确率,如果使用更先进的 ResNet(或者搭配 Siamese Net) ,可能能够在较小的轮次里达到更好的效果。
结果总结
- 训练集:企业给的 10k 数据集中的 $\frac{3}{4}$ 。
- 验证集:企业给的 10k 数据集中的 $\frac{1}{4}$ 。
- 测试集:企业未给出的 5k 数据集,用来测试模型性能以及评分。
- 验证集和训练集不重复。
| 验证码类型 | 验证集准确率 | 测试集准确率 |
|---|---|---|
| 1 | 1.00 | 1.00 |
| 2 | 0.98 | 0.98 |
| 3 | 0.99 | 0.99 |
| 4 | 1.00 | 0.99 |
| 5 | 0.93 | 0.92 |
总结
在这篇文章中提到了五种难度依次递增的验证码类型,我们基于 VGGNet 的网络结构分别对其进行了神经网络模型的搭建。对于 变长和难度较大的验证码类型 ,我们对其进行了前期的 分割 操作;对于较为简单的验证码类型,我们则采用了 端到端 的方式对其直接进行建模。通过模型在验证集和测试集上的准确率,我们可以看出端到端的模型不但避免了前期困难的预处理工作,且能训练出高准确率的识别模型。由此可见端到端的训练模式将是未来深度学习的一个重要方向。
第五类验证码在使用单纯的分类学习时没有办法收敛,使用 triplet loss 进行相似度学习就可以得到较好的成效;这是因为第五类验证码具有差异性小和类别繁多的特点。
代码托管在 我的github 中。